
axi总线进阶内容
参考链接:
有关cache
axlock详细解析
锁访问
主要使用LOCK信号,锁住一笔传输,拒绝其它传输的干扰,只有这笔传输完成之后释放Lock信号,才可以进行其它笔传输。
- 在M0想要发起一笔锁定传输前,需要确保是否还有在进行的传输,必须要确保之前进行的传输都已完成。
- M0使用AxLOCK发起locked transaction,interconnect通过内部仲裁器确保只有M0能够访问S0,其它主机的访问都会被阻塞掉,直到锁定传输完成。
- AXI3支持锁定访问,但AXI4已经不支持了
独占访问
- AXI4取消锁定访问的原因是新增了独占访问,比锁定访问效率更高,还是使用AxLOCK信号。
- 锁定访问是不允许其它主机访问正在锁定访问的从机,而独占访问允许访问该从机,只是不允许其它主机访问相同的内存范围(memory range)。
- 这样既不会出现两个主机对同一块内存空间进行更改,导致数据错误;还可以一定程度保证了总线的最大带宽和总线延迟。
- 从机内部需要实现一个独占访问的monitor,用于记录独占事务序列的信息确定哪段地址区间被独占访问,以及识别正在执行独占访问的主机ID。
- RRESP[1:0]和BRESP[1:0]可以表示独占访问的成功或失败
| RRESP/BRESP | 响应 | 含义 |
|---|---|---|
| 00 | OKAY | 表示独占访问失败/正常访问成功 |
| 01 | EXOKAY | 独占访问成功 |
独占访问的过程
- (1)主机对slave的一个地址进行独占读操作,从机monitor记录下该master的ARID以及访问的地址位置
- (2)一段时间之后,主机对相同地址进行独占写操作,此时从机monitor同样记录下该操作主机的AWID和要访问的地址位置
- (3)将AWID与之前记录的ARID进行比对,如果一致,说明该地址之前并没有被其它主机访问,返回EXOKAY;否则返回OKAY,独占访问失败
另一个例子
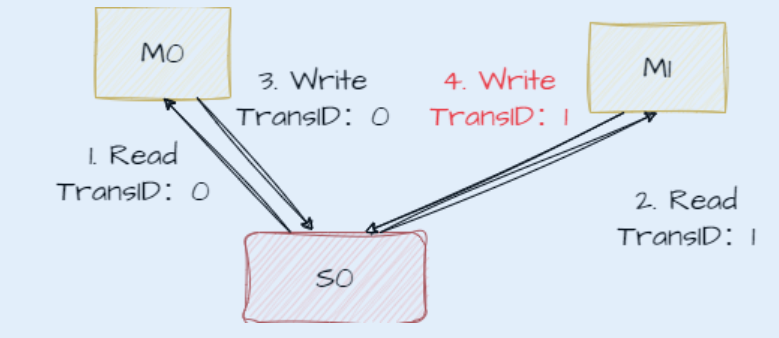
- 对于在独占写之前有多笔独占读,那么monitor所记录下来的ID都将存入一张表内,之后当开始独占写时,查找这张表,如果有ID相同的,则独占写传输成功。
- 由于该地址的数据已被更改,前面记录的ID会全部被清除,如果连着独占写,那么一定会失败,返回OKAY
axi总线死锁分析
两种死锁场景分别是乱序读和写交织,那就是out of order和interleaving。下面我们分析原因
乱序读:我们知道AXI协议支持乱序读,那么为什么能实现呢?这也是常见面试题目,那就是因为AXI(现在单指AXI3)每个通路都有相应的ID,通过请求和响应ID的一致来将打乱的顺序恢复
AXI-Stream反压机制
在现代数字系统设计中,无论是 FPGA 还是 ASIC,数据流的处理效率往往决定了整个系统的性能上限。AXI4-Stream 协议凭借其简洁、高效的特性,成为了数据流传输的事实标准。然而,许多工程师在使用 AXI-Stream 时,往往只关注数据的“流动”,而忽视了“堵塞”的处理——即反压(Backpressure)机制。
反压不仅仅是一个信号的拉低,它是一门关于时序收敛、吞吐量平衡与死锁避免的平衡艺术。本文将从设计哲学的角度,深入剖析 AXI-Stream 反压机制的底层逻辑与工程实现。
反压的时序表现
反压的本质,是接收端(Slave)通过拉低
TREADY告诉发送端(Master):“我处理不过来了,请暂停发送”。
下面是一个典型的反压时序图。
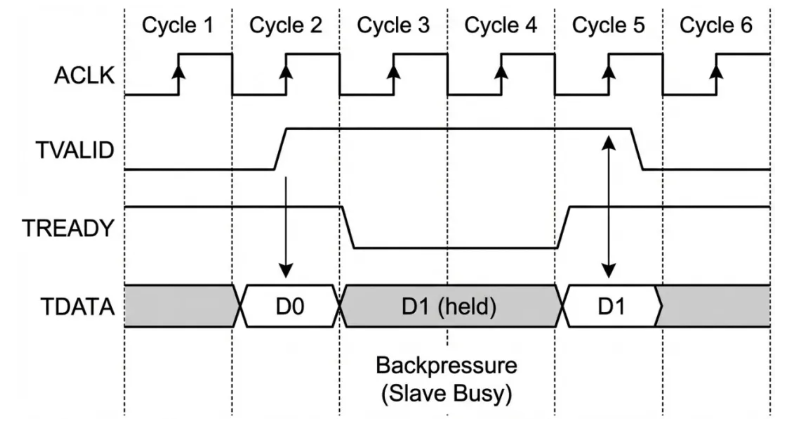
在 cycle 2,握手成功,传输 D0。在 cycle 3,Master 准备好了 D1(TVALID=1),但 Slave 忙碌(TREADY=0),产生反压。Master 必须保持 D1 和 TVALID 不变,直到 cycle 5 握手成功
$ y=x \oplus b $
H20
x2
高亮
note
测试
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 zhzhuang的博客!
相关推荐
2026-04-14
axi总线
参考文章链接: AMBA总线3-AXI 咸鱼IC 深入理解AMBA总线(十五)AXI-stream - 知乎 基本概述 AMBA3版本推出了AXI协议,它支持高性能、高频率的系统设计,其主要特点如下所示: 分离的地址/控制和数据阶段 通过字节选通方式支持非对齐的数据传输 使用基于突发的事务,只需其实地址发出。(Burst不得跨4KB边界,防止跨越Slave边界) 单独的读写数据通道,这可以提供低成本的直接内存访问(DMA) 支持发布多个超前地址(outstanding) 支持完成乱序事务(out-of-oder) 易于添加register stage达成时序收敛 AXI协议包括涵盖低功耗操作的可选扩展信号 AXI协议是基于突发的,并定义了五个独立的事务通道。地址通道携带着控制信息,用于描述传输数据的性质。五个独立通道都由一组信息信号、以及提供双向握手机制的VALID和READY信号组成。 Master使用VALID信号来显示信道上的addr、data或ctrl信息何时可用 Slave使用READY信号来显示它何时可以接受信息 读数据通道和写数据通道还包括LAST信号,以指...
2026-04-14
apb总线
APB发展 APB2 该规范定义了接口信号,基本的读写传输以及APB的两个组件APB bridge和APB slave APB3 定义了下面两个附件功能 等待状态,参见Transfer 错误报告,参见Error response 对应增加的信号如下 PREADY:准备就绪信号,表示APB传输完成 PSLVERR:传输失败的错误信号 APB4 定义了以下附加功能: 事务的保护,参见Protection unit support 稀疏数据传输,参见Write stobes 对应的信号如下 PPROT:一种保护信号,用于支持非安全事务和安全事务 PSTRB:一种写掩码信号,用于在写数据总线上实现稀疏数据传输 APB5 定义了以下附加功能 PWAKEUP信号 User信号 Parity protection and check信号 Reaml Management Extension(RME)支持 APB信号 数据总线 APB协议有两个独立的数据总线,一个用于读取数据,一个用于写入数据 总线可以达到32位宽 由于总线没有各自的握手信号,...
2026-04-14
ahb总线
AHB信号 AHB协议相比APB协议更加复杂,性能更加优越,手册上也清楚写明了它的特点:高性能、流水线、突发、多主机、分段传输,原文如下所示: 注意这是AHB2中的描述,到了AHB-lite和AHB5中,AHB协议本身不再支持多主机操作,也去除了仲裁相关的若干信号,但可通过添加Multi-layer interconnect组件实现多主机功能。也不再支持分段传输Split,去除了HSPLITx信号。因此和APB相比,最大的不同是AHB支持流水线操作和突发操作。 目前AHB协议有AHB2、AHB-lite、AHB5协议,AHB-lite的变化是在AHB2的基础上做了减法,而AHB5的变化是在AHB-lite的基础上做了加法。实际使用时可能不会分得太清,系统中需要某些信号可能就直接加上去了,不需要的可能直接就删除了,并不会太严格的说这是第几代AHB协议。但本着学习的目的,我还是想做下三代AHB协议的对比。 AHB协议使用一种读数据多路复用器互连方案。管理器向所有从属设备发出地址和控制信号,而在数据传输的数据阶段,解码器会选取适当的从属设备。来自所选从属设备的任何响...